by Jackson Armstrong
One of the most cryptic and alluring aspects of the pages of the Aberdeen council registers is the handwriting which appears in them. To most people this script is not remotely decipherable.
Patterns of handwriting change over time. The study of these changes is known as palaeography. An excellent public resource may be found at the Scottish handwriting website.
Even in 1591 the town clerk of Aberdeen reported his bafflement by the handwriting of the fourteenth century. That year the clerk, Master Thomas Mollisone, who was preparing an inventory of extant registers and bailie court books, found no volumes from earlier than 1380. However, he noted that ‘Befoir this, scrowis [scrolls] on parchment ’ written in Latin ‘and for ilk year ane skrow’, survived. In his assessment they were ‘evil to be red, be resoun of the antiquitie of the wreit and the forme of the letter or character … which is not now usit’ and that ‘skairslie gif ony man can reid the samyn’.1

The only extant burgh court roll, from 1317, kept at the Aberdeen City and Aberdeenshire Archives.
We think of the contents of the eight register volumes from 1398–1511 as a corpus of text. But what is ‘the text’? The task of our project is to take the handwritten script in the registers and render it as machine readable text. I think it is useful to pause and consider the difference between what we think of as ‘the text’ and the handwritten script. The scripts in these registers use a set of character symbols with standard abbreviations and also special letter forms. It is helpful to think of this as a form of shorthand writing, or even encryption, which it is our job to decipher. A later and more extreme version of such abbreviation, or shorthand, is that which was devised by Thomas Shelton, and used by Samuel Pepys in writing his well-known diary. The ‘text’ of Pepys’s diary entries (what might be described as their meaningful content) is not necessarily the same as the writing on the page. The editors of Pepys’ diaries had the difficult task to extract the ‘text’ from the diarist’s shorthand (for an example, see this image of a page of his diary). Similary, a difference can be noted between the text of our material, and the handwriting which various scribes used to symbolise that meaningful content. It is our interpretation of the handwritten script which produces ‘the text’.
This brings us to the nature of the transcription we produce by rendering the script into text. A diplomatic transcription aims to reproduce everything as it is, for instance giving wt for wt . By contrast, a semi-diplomatic transcription includes the full expansion, in this case expanding wt to ‘with’. It may even be possible to represent the set of symbols used for the original script with high fidelity, producing what is in effect a facsimile. For instance, a form of typeface called ‘record type’ was invented in the late eighteenth century to reproduce medieval abbreviations. That would be a tremendously cumbersome process and it would not help in moving from script to text. In addition, record type and full diplomatic transcription were invented before the benefit of modern photography. Digital images of the original pages now provide a perfect facsimile, and as a result a diplomatic transcription is no longer necessary.
Our task is not to create a facsimile of handwriting, but to represent the text as consistently and accurately as we can. To this end we aim to produce a text which may be displayed either as a semi-diplomatic transcription, or a semi-normalised transcription. The latter allows for fuller intervention by the transcriber, regularising and smoothing out features like variant letter forms, punctuation, capitalisation, and so on. In the former case, the expansion of abbreviations is assisted by the fact that these were standardised to a large degree. Reference works are available to assist transcribers with the identification and expansion of abbreviated forms.

ACR 4, p. 7, entry 2
semi-diplomatic transcription: Eodem die Johannes mercer’ adiudicatur in amerciamento curie pro iniusta de perturbacione ade de benyn vicini sui. Et dictus adam in amerciamento pro perturbacione predicti Johannis mercer’ et dictus Johannes mercer’ dedit Johannem vokate patrem plegium legalem quod dictus adam erit indempnis de ipso et perturacione sua aliter ipse per viam iuris Et modo consimili dictus adam dedit Ricardum de Ruthirfurd plegium legalem quod Johannes mercer’ erit indempnis et cetera.
semi-normalised transcription: Eodem die Johannes Mercer’ adiudicatur in amerciamento curie pro iniusta de perturbacione Ade de Benyn vicini sui. Et dictus Adam in amerciamento pro perturbacione predicti Johannis Mercer’ et dictus Johannes Mercer’ dedit Johannem Vokate patrem plegium legalem quod dictus Adam erit indempnis de ipso et perturbacione sua aliter ipse per viam juris. Et modo consimili dictus Adam dedit Ricardum de Ruthirfurd plegium legalem quod Johannes Mercer’ erit indempnis et cetera.
In our project we are not doing all this for paper and ink, but electronically, and through Text Encoding Initiative (TEI) annotation. A useful essay on this process is by M J Driscoll, on ‘Electronic Textual Editing: Levels of transcription’.2 Thus the text we produce is not just typed out as ‘flat’ strings of characters and words (as it would be in an edition printed on paper), but it is encoded following TEI standards. This allows the text to be augmented with annotations concerning the structure of the text, features of the transcription and textual meaning. These annotations, for example, enable us to indicate where we have made an expansion by supplying in full the information represented by the abbreviation in the original script.
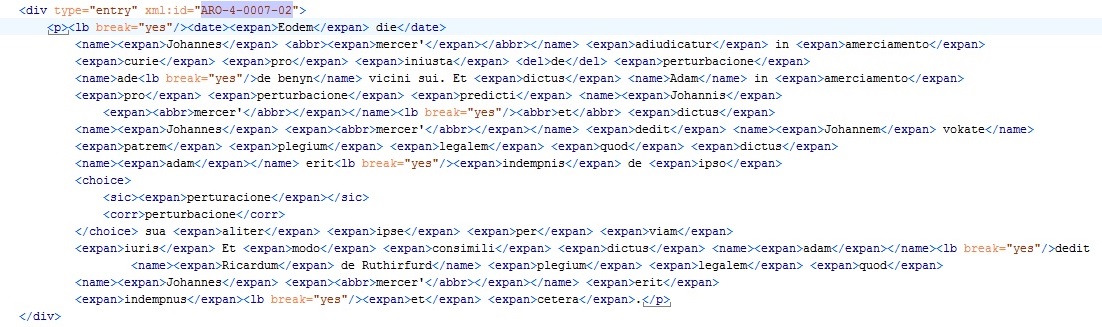
TEI-annotated transcription of ACR 4, p. 7, entry 2.
However, a pertinent question is whether a silent expansion of a standard abbreviation may still be a consistent and accurate representation of meaningful content when moving from original script to electronic text. Indeed, the choices made by the transcription team as to how to interpret particular characters in the script rely on a process of judgement, partly based on interpretation of context. Cumulatively, those judgements will result in the transcribed text. In all this they follow a process which enables cross-checking to ensure a high degree of inter-transcriber agreement and consistency, both on the transcribed corpus of text, and on the annotations made to augment that corpus.
The process of moving from original script to electronic text is fundamental to our work. It presents its own challenges and choices which take a range of skills to address, and to ensure the final product is robust and reliable.










